
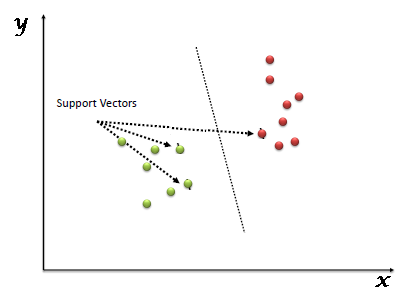
SVM(Support Vector Machine) is a machine learning algorithm used for both classification and regression problem.It is mainly used for Classification problem in which the set of training examples is divided into further parts. we perform classification by finding the hyper-plane that differentiate the two classes very well (look at the below snapshot).

There are ways by which we can plot a SVM:-
- Identify the right hyper-plane (Scenario-1): Here, we have three hyper-planes (A, B and C). Now, identify the right hyper-plane to classify star and circle.
You need to remember a thumb rule to identify the right hyper-plane: “Select the hyper-plane which segregates the two classes better”. In this scenario, hyper-plane “B” has excellently performed this job.

Identify the right hyper-plane (Scenario-2): Here, we have three hyper-planes (A, B and C) and all are segregating the classes well. Now, How can we identify the right hyper-plane?

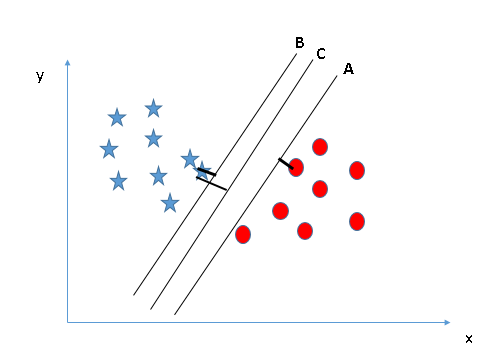
Here, maximizing the distances between nearest data point (either class) and hyper-plane will help us to decide the right hyper-plane. This distance is called as Margin.
In the next blog I will be talking about my my week-8 which is totally about Unsupervised learning.
Image source-www.analyticsvidhya.com


















{kind=link}